
Dual Neural Style Transfer with Docker Compose
How to extend NST with a second style and what are the challenges of deploying it as a single unit using TensorFlow, Flask, ASP.NET Core, Angular and Docker Compose.
Programming is easy like riding a bike. Except the bike is on fire and you're on fire and everything is on fire and you're actually in hell.

The picture is generated by the application under discussion, its content is taken from Jeff Atwood who took it from Steve McConnell’s book, Code Complete.
A live demo is available at http://nst-online.evgeniymamchenko.com.
The sources are available at https://gitlab.com/OutSorcerer/NeuralStyleTransferWeb. There you will also find the instructions on how to launch the application locally with Docker Compose.
- How to use the application
- What is neural style transfer?
- How I extended the original neural style transfer algorithm
- Architecture
- Challenges
- Possible improvements and further reading
- Credits
How to use the application
-
Click on the “Content Image” button or the placeholder below and upload a content image.
-
Pick a style image.
-
Optionally pick a second style image.
-
Optionally change the parameters.
-
Iterations. The number of optimization steps taken. The higher the number, the lower the cost and, generally, the more beautiful the result.
-
Content cost weight. The multiplier of the content cost term in the total cost. The higher the number, the more similar to the content image the result is.
-
Style cost weight. The multiplier of the style cost term in the total cost. The higher the number, the more similar to the style image the result is.
-
-
Click “Launch” button. The transfer is starting, the resulting image and other transfer details are shown on the screen.

This is how the UI looks in the middle of a style transfer when two styles (a starry sky and neon lights) are simultaneously applied to a single content image.
Please note that http://nst-online.evgeniymamchenko.com works just on 2-cores machine, where 100 iterations of transfer take about 30 minutes. My mobile GPU Nvidia GeForce GTX 1050 works about 100 times faster. Unfortunately, a GPU in the cloud is too expensive right now (one of the cheapest GPU instances with Nvidia TESLA K80 Module costs about $270 per month).
If your job status is “queued”, that means that the back-end is busy at the moment, but it will start processing your input as soon as all previous jobs are done.
-
Click “Stop” button to abort the transfer.
What is neural style transfer?
Intuitively it can be defined as generating a picture which content is similar to one input image and which style is similar to another input image.
In a more detailed way, it is a result of iterative optimization of a specific cost function defined on a resulting image. On each step of the optimization, we compute the gradient of that cost function with respect to each pixel of resulting image and slightly change the resulting image in the direction opposite to the gradient as we always do in the Gradient descent algorithm.
The interesting fact here is that, typically, when training convolutional neural networks, images are fixed and weights of the network are the subject of optimization. On the contrary, in NST algorithm the weights of CNN are fixed, while the input image is being optimized. In the original paper the CNN with VGG architecture pre-trained on ImageNet dataset. This application also loads weights of pre-trained VGG model. What is interesting is there could be something special in VGG architecture that makes it especially good for neural style transfer although some people achieved good results with other architectures too.
The mentioned cost function is the sum of two terms.
The first one is the content cost multiplied by its weight (a parameter that can be configured in UI as mentioned above). The content cost is the squared Euclidean distance between (the squared L2-norm of the difference of) the values of an intermediate convolution layer on the content image and the resulting image normalized by the input size.
The second one is thereafter the style cost multiplied by the style cost weight parameter.
Unlike the content cost, the style cost is computed on multiple layers, the style costs for each level are multiplied by their weights (which are also model parameters) and summed up to give the total style cost. In the context of this application, there are five such layers, each weight is equal to 0.2 and cannot be changed from the UI yet. The shallower layers are responsible for lower-level features like those that detect horizontal lines, vertical lines, diagonal lines and other simple geometrical shapes, while deeper layers are responsible for higher-level features like those that detect parts of objects or entire objects like eyes, flowers, cars, cats and dogs, although sometimes it is pretty hard to figure out what a particular feature detects.
For a single layer, the style cost is the squared Euclidean distance between Gram matrices of that layer activations (with (number_of_channels, height*width) shape) for the resulting image and the style image.
Gram matrix is approximately proportional to the covariance matrix (in case values are centered). Its diagonal elements are just squared L2 norms of the corresponding channel activations reshaped as one-dimensional vectors.
For a detailed explanation of neural style transfer you can see the original paper, read my source code or watch the video and complete the corresponding programming assignment from the Coursera CNN course, on which my code is based (all the videos are available for free on YouTube but Coursera subscription is required to complete the programming assignment).
How I extended the original neural style transfer algorithm
To make the application more interesting, I decided to extend the original algorithm. What if we try to apply two styles simultaneously? Surprisingly, it worked quite well: styles are not overlapping but rather being applied to different parts of the image, depending on which part is more suitable for each style. Let us call it “dual NST”.
See the example illustration above.
To implement a second style an extra style term is added to the total cost.
Feel free to play with it yourself, I would appreciate if you would share your results in comments.
Architecture
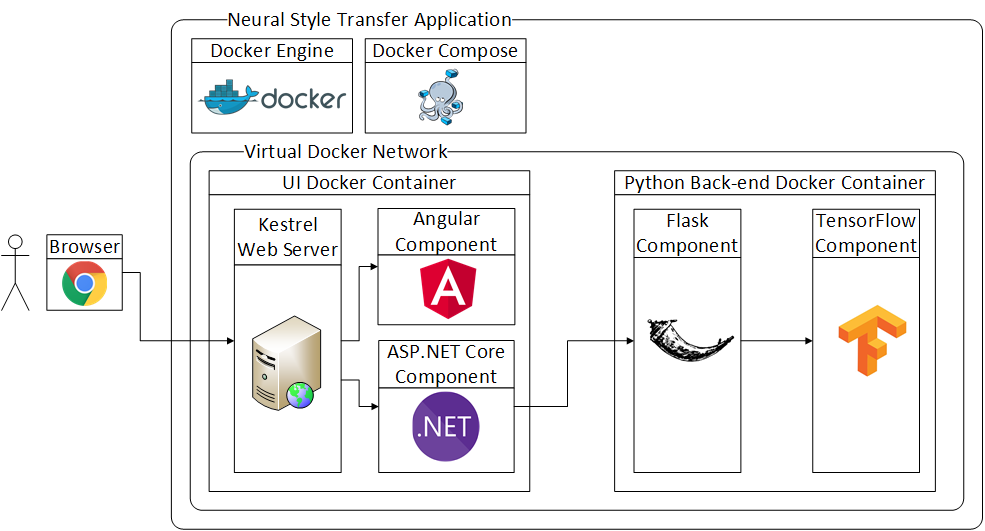
Let us talk in more detail about the building blocks of the application.
Angular
Angular 5 component is the face of the application. It is responsible for validating a user’s input and sending it to the server.
When a transfer job is in progress, it does polling with a one-second interval to show results in real time. rxjs is a nice tool for filtering, mapping and combining streams of asynchronous events where tasks like HTTP polling are solved in a powerful and concise way. For example, if some request was not able to complete in one second and the next request already started, it would make no sense to wait for both of them and waste connections, as the data from the previous request would be already obsolete. switchMap operator nicely solves this problem:
const polling = Observable.timer(0, 1000)
.switchMap(() => this.http.get<any>(this.baseUrl + `api/neural-style-transfer/jobs/${jobId}`));
Angular 5 is my framework of choice because of my love to statically typed languages like C# or TypeScript and also because of the nice SPA template included with .NET Core CLI. That template is even capable of the server-side rendering, which is a nice tool for SEO and improving the user experience, as it significantly decreases the initial page load time.
The template (and this application) uses Bootstrap library which looks a bit old-fashioned in 2018, I hope the next template from Microsoft will use Angular Material which is more modern-looking.
Considering React vs. Angular, I prefer Angular because, among other things, it is a whole framework with “batteries included” experience featuring things like built-in Dependency Injection, which could be very useful for tests. So you have fewer decisions to make in the beginning, while it is still highly extendable (for example, if you would like, you could use Redux-like @ngrx/store).
ASP.NET Core
The ASP.NET Core component receives REST requests from the Angular SPA, resizes images to 400x300 and puts NST jobs in a queue. Since TensorFlow uses 100% of CPU power, it is not practical to perform two transfers simultaneously, that is why that queue comes in handy. The ASP.NET Core component is also responsible for responding to the polling from the Angular SPA and doing the polling of Python back-end itself.
C# is my favorite language so the choice of ASP.NET Core is natural for me. Microsoft is doing a great job of improving the C# language (comparing with Java, C# syntax recently was and still is years ahead) and building great tools for the developer productivity like Visual Studio and VS Code (and, thanks to JetBrains there are also great extensions/alternatives like ReSharper or Rider). I admit that the open-source community around C# is not as productive as Java or Python communities, but considering that the framework itself and many Microsoft libraries became open-source and cross-platform and Microsoft supports others in building open-source software based on .NET, everyone should take a closer look at .NET Core.
Also, using C# here is a nice example of how two micro-services written in different languages possibly by different teams could easily communicate using REST. Python is very popular for machine learning, but in other spheres, people may use Java, .NET, Node.js, etc. so this scenario is what we would often see in the real world.
Flask
Flask is a popular Python framework for building Web APIs including RESTful ones.
It wraps around the TensorFlow model which is running in a background thread while on another thread it responds to requests to start, stop or query a status of an NST job.
Even though there are special flask_restful and flask_jsonpify packages creating REST/JSON services seems to be not so smooth with Flask as it is with ASP.NET Core. I believe it is not only my lack of experience with it because some parts of my code are based on high-ranked answers on Stack Overflow and instead of using some built-in function they are suggesting to copy-paste their implementations of it.
To be more clear here is an example of parsing of an HTTP request body in JSON format:
# This decorator takes the class/named tuple to convert any JSON data in incoming request to.
def convert_input_to(class_):
def wrap(f):
def decorator(self, *args):
obj = class_(**request.get_json())
return f(self, obj)
return decorator
return wrap
@convert_input_to(BackendJobModel)
def put(self, job):
# ...
current_job = job
Looks nice, but what if a decorated function had more arguments? I could rewrite the code, of course, but the point is, there should be a built-in and generic solution out-of-the-box in contrast to making users copy-paste code that performs very basic tasks.
For comparison the similar place in ASP.NET Core does not use any custom code and looks like this:
[HttpPut("jobs")]
public ActionResult StartJob([FromBody] JobModel model)
{
// ...
}
I would appreciate if someone would recommend me a nicer replacement of Flask for REST on Python.
TensorFlow
TensorFlow is an open-source software library for numerical computation using data flow graphs. It has a built-in gradient computation, many supported operations from simple matrix addition or multiplication to pre-implemented convolution or sampling layers, optimizers from GradientDescentOptimizer to AdamOptimizer, ability to run on GPUs and TPUs and many more which makes it one of the most popular tools for building neural network models.
The program starts with loading weights of the pre-trained VGG network and building a computational graph. A nice thing is that a single graph and a single TensorFlow session can be used for handling different user inputs which makes initialization time much faster.
Since initialization and training take significant time, but we want to keep a user up to date by responding to HTTP requests, TensorFlow code works in a separate thread.
This code is based on an assignment Art Generation with Neural Style Transfer from Andrew’s Ng course, which is a part of the Deep Learning specialization.
My changes include the support for a second style image that I described above and various performance improvements that I am going to describe below.
Docker Compose
Docker as a containerization software that provides an immutable environment which helps a lot with making deployment predictable and reducing time expenses for it. That is useful both for Python and .NET Core / Angular parts of the application. They are both wrapped into Docker containers.
Docker Compose is, in turn, a tool to run multi-container applications. One of its abilities is virtual networks where we can put our services so that they are visible to each other, but not to the outside world. In this example, the Python container should not communicate with a user directly so it does not publish any ports to outside and it can only receive requests from the .NET Core container, which, on the contrary, publishes port 80 to receive user requests.
With Docker and Docker Compose you can launch this application just in minutes without spending much time on environment preparation (which might be a tedious task). You will find the detailed instructions in the README file of the corresponding GitLab repository.
Challenges
It was fun to work on this project. But, unfortunately sometimes your code fails, it could be not your guilt, but it is your responsibility to make everything work. There was plenty of moments when something was not working and I had no idea why, that is the reason I chose Coding Horror illustration for this post. But more satisfying it was to finally figure everything out.
Installing TensorFlow with GPU support on Windows
TensorFlow itself installs easily by following the official instructions with just pip install, but Nvidia could definitely try better with deploying their seriously great software to an end-user.
CUDA 9.0 (with tensorflow-gpu 1.8.0 package you need exactly CUDA 9.0 version, not the most recent one) itself is wrapped in a nice installer, but unfortunately it fails to install Visual Studio integration module and does not even try to install other modules afterwards even though they do not depend on the VS integration.
Luckily, they have a forum where the user oregonduckman posted his workaround. I was even able to simplify it a bit and also contributed to that forum thread. The solution was surprisingly simple: install everything except VS integration, unzip installer file as an archive and manually launch executables in the VS integration folder. Another unobvious step was that you should not install the latest GPU driver, instead, you may need to remove existing Nvidia GPU driver by replacing it with a generic one prior to the CUDA installation. Also, see the official installation instructions.
cuDNN installation is even more a shame since here you have to copy some files manually from unzipped “installer” and manually set some environment variables.
I hope I live to see the day when NVidia finally makes a proper installer or maybe even starts using a Windows package manager like Chocolatey.
Docker could help here a lot, but unfortunately using GPU from Docker is not possible on Windows right now. Although I could imagine it working in a bright future, as the answer to the question “Why is it not possible?” looks promising: “No not possible, we would need GPU passthrough (i.e DDA) which is only available in Windows server 2016.” If it worked on Windows Server, it could come to other editions of Windows as well.
The communication between .NET Core and Python
My first approach to this was launching a Python process from .NET Core by System.Diagnostics.Process.Start. At first, it looked as a nice and simple while cross-platform way, but it had a number of disadvantages.
How is .NET Core supposed to pass parameters and input images to Python? How should Python pass resulting images and costs to .NET Core? On Windows and Linux there are various ways of inter-process communication like named pipes or sockets, but they are not cross-platform. So initially I chose a common temporarily folder as a mean of communication. The .NET Core process was just placing input files there and passing transfer parameters like iterations count as command-line arguments to the Python process. The Python process, in turn, was writing result files in that folder and the .NET Core process was subscribing to changes in that folder with FileSystemWatcher.
A big disadvantage was that the 500Mb weights of the pre-trained VGG network were reloading from disk to memory for each transfer job. TensorFlow graph was also rebuilding from scratch each time. All that was resulting in initialization time of about one minute.
The solution was to the make Python process long-running and communicate with it by REST with help of Flask framework. So the weights are now loaded just once, the graph is built just once and, as a result, the request initialization time on GPU went from one minute to thirty seconds.
Since the traffic between .NET Core and Python components is quite small (about 300 kB per second) HTTP/JSON is fine for this use-case. In case that would become a bottleneck something like WebSocket and a binary serialization protocol like Protocol Buffers could be used. Another alternative is Google’s gRPC.
The usage of the server-side rendering and Angular from .NET
I mentioned above that I used a nice Angular 5 template for .NET Core. The issue is that in the current (2.0) version of .NET the CLI for .NET or Visual Studio this template is missing but there is the Angular 4 template instead.
I foolishly tried to update it manually to Angular 5, that initially worked fine. But as soon as I started to build Docker images, that included building the Angular 5 application in production mode with SSR, it broke. It turned out that there were breaking changes in SSR from Angular 4 to Angular 5.
I was already choosing between giving up SSR or giving up Angular 5 when I luckily found that Microsoft created the new SPA template with the support of both Angular 5 and SSR (although SSR is not turned on by default). The point was that template was still in beta and it had to be installed manually with
dotnet new --install Microsoft.DotNet.Web.Spa.ProjectTemplates::2.0.0
and used by
dotnet new angular
When .NET Core SDK 2.1 is released, that will not be required anymore.
Leaking TensorFlow graph nodes (and therefore memory)
The original implementation of NST from the Deep Learning specialization on Coursera worked nicely when it was launched just once or twice from Jupiter notebook. But, as it turned out, it was not production-ready at all.
The first thing, that caught my eye, was that content cost and style cost nodes of the computation graph in TensorFlow were not reused but created for each input image:
# a_C was a NumPy array (not a Tensor) with an activation of a hidden layer
# when a network input is set to a content image
# a_G was also a NumPy array with the same activation
# when a resulting image is set as a network input
# J_content is the content cost tensor (a graph node in a computation graph)
J_content = compute_content_cost(a_C, a_G)
It was rewritten as:
a_C_var = tf.Variable(np.zeros(out.shape), trainable = False, dtype = 'float32')
J_content = compute_content_cost(a_C_var, a_G)
The same was done for the style cost, the content cost weight, the style cost weight and the total cost.
That allowed to reuse their graph nodes just by assigning new values to the corresponding variables. That was done intuitively in the attempt to cache what can be cached considering that the initialization time at the moment was too long. That ended up to be a step in the right direction, but a serious problem still remained.
I also realized that a current session must not be created from scratch for each transfer but a single session can be reused.
Everything seemed to be perfect, I deployed the application to a Google Cloud instance and started to test it more intensively. And then I faced “out of memory” errors. At first, I thought that it is just a peculiarity of the Python/TensorFlow memory management and it can be solved just by increasing the instance memory but that just postponed the error, not fixed it entirely. I looked at the TensorFlow process memory consumption and saw that it was steadily growing.
Long story short, the reason was leaking TensorFlow computation graph nodes, specifically assign nodes.
Unlike an assign operation from C++ or Python, an assign operation in TensorFlow is just another graph node. Using these operations to set variables to new inputs was adding new and new nodes to a graph, which was causing “out of memory” errors.
More accurately, the assign operation itself is not consuming memory, but it implicitly creates a constant node with an assigning value.
By the way, there is a nice way to validate if you program is free of such kind of bugs, by adding tf.get_default_graph().finalize() immediately before the training loop. It is not done automatically just because it would break a huge amount of existing code. But maybe it would be a good thing…
So, instead of:
session.run(input_variable.assign(content_image))
there must be:
input_placeholder = tf.placeholder(dtype='float32', shape=(1, CONFIG.IMAGE_HEIGHT, CONFIG.IMAGE_WIDTH, CONFIG.COLOR_CHANNELS))
graph['input'] = tf.Variable(input_placeholder, dtype = 'float32')
during initialization, and then for each request:
session.run(input_variable.initializer, feed_dict = {input_placeholder: content_image})
You must also remove:
session.run(tf.global_variables_initializer())
Because that would also try to initialize variables like input_variable without defining the corresponding placeholder values which would cause an error. Each variable must be initialized manually instead.
You will most likely also have to initialize the variables implicitly created by the optimizer. It can be done like:
# The following line must be executed only once before the computation graph is finalized.
optimizer_variables_initializer = tf.variables_initializer(optimizer.variables())
# The following line should be executed for each transfer.
session.run(optimizer_variables_initializer)
That fix also sped up the application significantly. A second run with a GPU started to initialize just in a few seconds instead of half a minute.
Here is a post on KDnuggets with more typical problems in TensorFlow graphs.
Broken switchMap
switchMap is a nice operation except it does not work. When I opened network tab in Chrome debugging tools, I was shocked as I saw that requests were not cancelled when they were taking more than one second, instead they were running indefinitely and, what was even worse, they were piling up and, since Chrome executes just a limited number of requests, that meant that pending time for each new request was growing.
So why switchMap may not work? It is obvious, you just need to replace
import { Observable } from "rxjs";
with
import { Observable } from "rxjs/Observable";
and it starts to work. In exchange for that you now have to explicitly import every rxjs operator that was previously imported automatically like
import 'rxjs/add/operator/switchMap';
Why it helps? I do not know, but the good thing is they fixed it in 6.0 version. Thanks to Airblader who created a GitHub issue where I found this.
Long response times
But why HTTP requests where taking so long for server to handle in the first place? Responses were just about 300 kB, so it was not the Internet speed.
The reason was that the TensorFlow thread was using 100% CPU, so there were not enough resources for the Flask thread and for the ASP.NET Core process.
Another consequence was weird exceptions from ASP.NET Core application:
System.InvalidOperationException: The SPA default page middleware could not return the default page '/index.html' because it was not found,
and no other middleware handled the request.
Your application is running in Production mode, so make sure it has been published, or that you have built your SPA manually. Alternatively
you may wish to switch to the Development environment.
at Microsoft.AspNetCore.SpaServices.SpaDefaultPageMiddleware.<>c__DisplayClass0_0.<Attach>b__1(HttpContext context, Func`1 next)
at Microsoft.AspNetCore.Builder.RouterMiddleware.<Invoke>d__4.MoveNext()
--- End of stack trace from previous location where exception was thrown ---
Luckily Docker Compose file format has a solution for that:
version: '2.3'
services:
neural-style-transfer-ui:
cpu_shares: 4096
neural-style-transfer-backend:
cpus: 1.9
cpu_shares: 1024
cpus sets the maximum number of cores that a service can occupy (in that case there was two-core instance).
cpu_shares sets a weight of a service, which takes effect only during the moments when CPU resources are limited.
I was confused at first by the fact that those settings were removed in the version 3 of the Compose file format. The reason is that the version 3 is mainly for running stacks of containers in Docker Swarm, which has its own way of limiting CPU usage, while the version 2 is for good old Docker Compose. And the version 2.3 is not so old as it was introduced almost at the same time as 3.4.
To make it even easier for the server I started to send the resulting image only when it changes. On a two-core instance it happens once in about 15 seconds, and the image size is about 300 kB, while for the rest of polling responses, that are performed each second, payload size is just a few hundreds of bytes.
Possible improvements and further reading
Feed-forward neural style transfer
The Deep Learning field is developing incredibly fast, and the original neural style transfer paper called A Neural Algorithm of Artistic Style from September 2, 2015 already became obsolete in terms of the implementation details of the style transfer idea (while the idea itself is still actual, moreover, it had a huge impact even outside of the scientific community).
One major breakthrough was the following paper that introduced a fast feed-forward method of neural style transfer, Texture Networks: Feed-forward Synthesis of Textures and Stylized Images from March 10, 2016. That method involves just a single forward propagation through a neural network instead of an iterative process and thus it is few orders of magnitude faster. The trade-off is that a network must be trained in advance for each style image and that process is even slower than the original style transfer iterative process. You can try that algorithm online.
Another paper that proposed a feed-forward method was Perceptual Losses for Real-Time Style Transfer and Super-Resolution from March 27, 2016. It looks like it is cited more often, but it appeared a bit later.
The next great discovery was a method of arbitrary style transfer that generalized the previous feed-forward approach to an arbitrary style in ZM-Net: Real-time Zero-shot Image Manipulation Network from March 21, 2017.
Other approaches to arbitrary style transfer are Exploring the structure of a real-time, arbitrary neural artistic stylization network from August 24, 2017 and Universal Style Transfer via Feature Transforms from November 17, 2017.
See a Medium post with an overview of the history of NST.
So, the next step for my application could be the replacement of the current iterative implementation with a feed-forward one based on one of the previous papers. What could still be challenging is how to implement it with a second style.
An arbitrary image size and proportions
The current implementation like the underlying VGG network can only process images of the fixed size (400x300), so if a chosen image size is different, it is resized by .NET Core application, before it is assigned as an input of a neural network.
In a recent post on fast.ai Jeremy Howard mentioned adaptive pooling layers, which could help to process an image of an arbitrary size (as far as I understand it is based on Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition). That would be useful for neural style transfer too.
Processing multiple user requests simultaneously
The bottleneck of the application is an optimization process in TensorFlow. Although multiple transfers are queued, the slow speed of a transfer on CPU makes it impractical on multi-user scenarios.
With GPU the performance is much better, but still, currently, only a single user at a time can have his transfer running, while others will wait in a queue. Running two TensorFlow sessions simultaneously is not stable, most likely due to GPU memory allocation.
On my 2GB GPU an attempt to run two TensorFlow sessions from two Python processes results in the following error:
2018-06-03 00:15:43.736350: E T:\src\github\tensorflow\tensorflow\stream_executor\cuda\cuda_dnn.cc:455] could not create cudnn handle: CUDNN_STATUS_ALLOC_FAILED
2018-06-03 00:15:43.741649: E T:\src\github\tensorflow\tensorflow\stream_executor\cuda\cuda_dnn.cc:427] could not destroy cudnn handle: CUDNN_STATUS_BAD_PARAM
2018-06-03 00:15:43.747966: F T:\src\github\tensorflow\tensorflow\core\kernels\conv_ops.cc:713] Check failed: stream->parent()->GetConvolveAlgorithms( conv_parameters.ShouldIncludeWinogradNonfusedAlgo<T>(), &algorithms)
That could be solved by using multiple machines with multiple replicas of the Python Docker container. That would also require Docker Swarm, Kubernetes or another orchestrator that runs against a cluster instead of Docker Compose, which runs against a single machine.
An alternative solution is the usage of distributed TensorFlow on a cluster.
TensorFlow Serving
TensorFlow Serving does not seem to be applicable currently, as it serves an already trained model, but here is a training process. However, with a feed-forward approach, it could replace the Flask part.
Moreover, it can also serve multiple models on a single GPU simultaneously.
Credits
Thanks to Andrew Ng and the whole deeplearning.ai and Coursera teams for their great work on the Deep Learning specialization.
Thanks to GitLab.com for generously providing 10Gb repositories for free without limits on individual files sizes (unlike 100Mb limit for a single file size on GitHub).
Thanks to Google Cloud for their $300 / 12-month Free Tier where the application is running now.
Thanks to my wife for her support and valuable advice.